Basic Collaborative Filtering Method (Nearest Neighbors Clustering)#
We are creating a collaborative filtering based movie recommendatipon system where are trying to create user-movie rating matrix (Matrix Factorization), where ratings given by users are playing features/ patterns role and based on nearest neighbours algorithm finding closest movies based on those patterns. Kind of finding similiar movies/ item-item similarity based recommendation system.
References#
https://www.geeksforgeeks.org/recommendation-system-in-python/
[1]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Loading data#
Ratings#
[2]:
ratings = pd.read_csv('/opt/datasetsRepo/RecommendationData/ratings.csv')
ratings.head()
[2]:
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 |
| 1 | 1 | 3 | 4.0 | 964981247 |
| 2 | 1 | 6 | 4.0 | 964982224 |
| 3 | 1 | 47 | 5.0 | 964983815 |
| 4 | 1 | 50 | 5.0 | 964982931 |
Movies#
[3]:
movies = pd.read_csv("/opt/datasetsRepo/RecommendationData/movies.csv")
movies.head()
[3]:
| movieId | title | genres | |
|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 1 | 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
General Shapes Information#
[4]:
print(f"""
ratings dataframe shape :{ratings.shape}
movies dataframe shape :{movies.shape}
total movies : {movies.movieId.unique().shape}
total rated movies : {ratings.movieId.unique().shape}
total users : {ratings.userId.unique().shape}
All kind of ratings given by users : {ratings.rating.unique()}""")
ratings dataframe shape :(100836, 4)
movies dataframe shape :(9742, 3)
total movies : (9742,)
total rated movies : (9724,)
total users : (610,)
All kind of ratings given by users : [4. 5. 3. 2. 1. 4.5 3.5 2.5 0.5 1.5]
Get unique ids#
[5]:
all_user_ids = ratings.userId.unique()
all_movie_ids = movies.movieId.unique()
Creating Maps#
Map to convert user id to user mapping id#
[6]:
user_id_maps = { i[0]:i[1] for i in enumerate(all_user_ids) }
Map to convert user mapping id to user id#
[7]:
user_id_inv_maps = { user_id_maps[i]:i for i in user_id_maps }
Map to convert movie id to movie mapping id#
[8]:
movie_id_maps = { i[0]:i[1] for i in enumerate(all_movie_ids) }
Map to convert movie mapping id to movie id#
[9]:
movie_id_inv_maps = { movie_id_maps[i]:i for i in movie_id_maps }
user-movie average rating#
[10]:
user_movie_ratings_df = ratings[['userId','movieId','rating']]\
.groupby(by=['userId', 'movieId'],as_index=False)\
.mean()
[11]:
user_movie_ratings_df.columns
[11]:
Index(['userId', 'movieId', 'rating'], dtype='object')
[12]:
user_movie_ratings_df.head()
[12]:
| userId | movieId | rating | |
|---|---|---|---|
| 0 | 1 | 1 | 4.0 |
| 1 | 1 | 3 | 4.0 |
| 2 | 1 | 6 | 4.0 |
| 3 | 1 | 47 | 5.0 |
| 4 | 1 | 50 | 5.0 |
Converting existing ids to mapping id#
[13]:
user_movie_ratings_df['user_maps'] = user_movie_ratings_df['userId'].apply(lambda x: user_id_inv_maps[x])
user_movie_ratings_df['movie_maps'] = user_movie_ratings_df['movieId'].apply(lambda x: movie_id_inv_maps[x])
[14]:
user_movie_ratings_df.head()
[14]:
| userId | movieId | rating | user_maps | movie_maps | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 0 | 0 |
| 1 | 1 | 3 | 4.0 | 0 | 2 |
| 2 | 1 | 6 | 4.0 | 0 | 5 |
| 3 | 1 | 47 | 5.0 | 0 | 43 |
| 4 | 1 | 50 | 5.0 | 0 | 46 |
Creating User-Movie Rating Matrix#
[15]:
from scipy.sparse import csr_matrix
[16]:
user_maps = user_movie_ratings_df.user_maps.values
movie_maps = user_movie_ratings_df.movie_maps.values
rating_values = user_movie_ratings_df.rating.values
rating_matrix = csr_matrix((rating_values, (movie_maps, user_maps))).toarray()
[17]:
rating_matrix
[17]:
array([[4. , 0. , 0. , ..., 2.5, 3. , 5. ],
[0. , 0. , 0. , ..., 2. , 0. , 0. ],
[4. , 0. , 0. , ..., 2. , 0. , 0. ],
...,
[0. , 0. , 0. , ..., 0. , 0. , 0. ],
[0. , 0. , 0. , ..., 0. , 0. , 0. ],
[0. , 0. , 0. , ..., 0. , 0. , 0. ]])
So How is this working actually
user_maps = [0 1 2 3 4 5 6 7 8 9 10]
movie_maps = [0 1 2 3 4 5 6 7 8 9 10]
ratings = [3 4 1 5 5 2 5 1 1 4]
Users maps
0 1 2 3 4 5 6 7 8 9 10
_ _ _ _ _ _ _ _ _ _ _
0 |3 0 0 0 0 0 0 0
1 |0 4 0 0 0 0 0
movies maps 2 |0 0 1 0 0 0 .
3 |0 0 0 5 0 0 .
4 |0 0 0 0 5 0 .
5 |0 0 0 0 0 2
6 |0 0 0 0 0 0
7 |. . . .
8 |. .
[18]:
rating_matrix.shape
[18]:
(9742, 610)
Clustering Model#
[19]:
from sklearn.neighbors import NearestNeighbors
[20]:
n_neighbors = 10
metric = 'cosine'
kNN = NearestNeighbors(n_neighbors= n_neighbors, algorithm='brute', metric=metric)
kNN.fit(rating_matrix)
[20]:
NearestNeighbors(algorithm='brute', metric='cosine', n_neighbors=10)
Testing Model#
[21]:
movie_id = 1
movies.query(f'movieId == {movie_id}')
[21]:
| movieId | title | genres | |
|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
[22]:
input_movie_vector = rating_matrix[movie_id_inv_maps[movie_id]].reshape(1,-1)
print("Input Movie Vector:",input_movie_vector.shape)
distances, collected_neighbours = kNN.kneighbors(
X=input_movie_vector, n_neighbors=n_neighbors, return_distance=True)
iter_map = map(lambda x: movie_id_maps[x], collected_neighbours[0])
recoms = movies[movies.movieId.isin(iter_map)].reset_index()
recoms['distances'] = np.round(distances[0], 3)
print("\nRecommendations :")
recoms.head(n_neighbors)
Input Movie Vector: (1, 610)
Recommendations :
[22]:
| index | movieId | title | genres | distances | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy | 0.000 |
| 1 | 224 | 260 | Star Wars: Episode IV - A New Hope (1977) | Action|Adventure|Sci-Fi | 0.427 |
| 2 | 314 | 356 | Forrest Gump (1994) | Comedy|Drama|Romance|War | 0.434 |
| 3 | 322 | 364 | Lion King, The (1994) | Adventure|Animation|Children|Drama|Musical|IMAX | 0.436 |
| 4 | 418 | 480 | Jurassic Park (1993) | Action|Adventure|Sci-Fi|Thriller | 0.443 |
| 5 | 546 | 648 | Mission: Impossible (1996) | Action|Adventure|Mystery|Thriller | 0.453 |
| 6 | 615 | 780 | Independence Day (a.k.a. ID4) (1996) | Action|Adventure|Sci-Fi|Thriller | 0.459 |
| 7 | 911 | 1210 | Star Wars: Episode VI - Return of the Jedi (1983) | Action|Adventure|Sci-Fi | 0.459 |
| 8 | 964 | 1265 | Groundhog Day (1993) | Comedy|Fantasy|Romance | 0.461 |
| 9 | 2355 | 3114 | Toy Story 2 (1999) | Adventure|Animation|Children|Comedy|Fantasy | 0.466 |
Plotting distances#
[23]:
fig, ax = plt.subplots(1,1, figsize=(3,5))
sns.barplot(data=recoms, y='title', x='distances', orient='h')
plt.show()
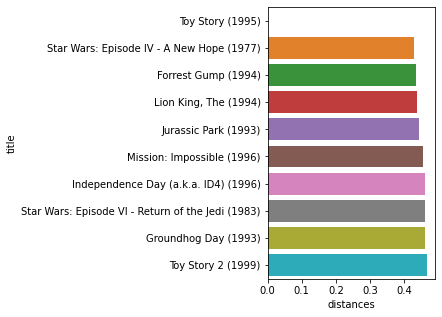
Recommendation System Modelling Class#
[25]:
from utils.engine import BasicMovieRecommedation
[26]:
model = BasicMovieRecommedation(n_neighbors=20)
model.fit(rating_df=ratings[['userId','movieId','rating']], movie_df=movies[['movieId']])
[27]:
movie_input = 1
print(movies[movies.movieId.isin([movie_input])])
movieId title genres
0 1 Toy Story (1995) Adventure|Animation|Children|Comedy|Fantasy
[28]:
movie_ids, distances = model.get_recommendations(movie_input, 5)
recommendations = movies[movies.movieId.isin(movie_ids)].reset_index()
recommendations['distances'] = np.round(distances, 3)
recommendations
[28]:
| index | movieId | title | genres | distances | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy | 0.000 |
| 1 | 224 | 260 | Star Wars: Episode IV - A New Hope (1977) | Action|Adventure|Sci-Fi | 0.427 |
| 2 | 314 | 356 | Forrest Gump (1994) | Comedy|Drama|Romance|War | 0.434 |
| 3 | 418 | 480 | Jurassic Park (1993) | Action|Adventure|Sci-Fi|Thriller | 0.436 |
| 4 | 615 | 780 | Independence Day (a.k.a. ID4) (1996) | Action|Adventure|Sci-Fi|Thriller | 0.443 |
| 5 | 2355 | 3114 | Toy Story 2 (1999) | Adventure|Animation|Children|Comedy|Fantasy | 0.453 |
[29]:
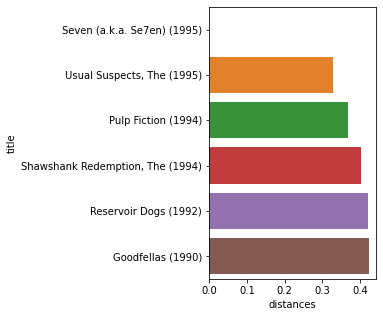
movie_input = 50
print(movies[movies.movieId.isin([movie_input])])
movieId title genres
46 50 Usual Suspects, The (1995) Crime|Mystery|Thriller
[30]:
movie_ids, distances = model.get_recommendations(movie_input, 5)
recommendations = movies[movies.movieId.isin(movie_ids)].reset_index()
recommendations['distances'] = np.round(distances, 3)
fig, ax = plt.subplots(1,1, figsize=(3,5))
sns.barplot(data=recommendations, y='title', x='distances', orient='h')
plt.show()
[31]:
movie_input = 605
print(movies[movies.movieId.isin([movie_input])])
movieId title genres
518 605 One Fine Day (1996) Drama|Romance
[32]:
movie_ids, distances = model.get_recommendations(movie_input, 5)
recommendations = movies[movies.movieId.isin(movie_ids)].reset_index()
recommendations['distances'] = distances
fig, ax = plt.subplots(1,1, figsize=(3,5))
sns.barplot(data=recommendations, y='title', x='distances', orient='h')
plt.show()
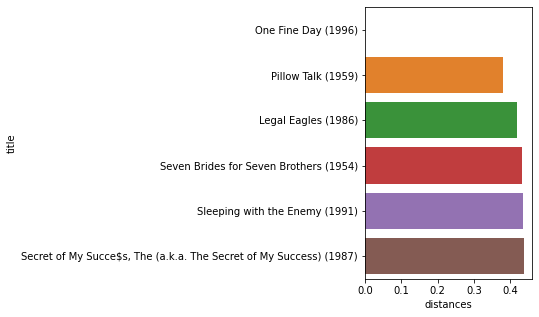
[33]:
movie_input = 999
print(movies[movies.movieId.isin([movie_input])])
movieId title genres
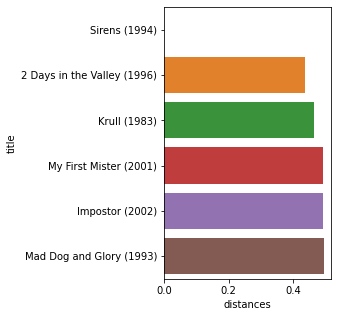
760 999 2 Days in the Valley (1996) Crime|Film-Noir
[34]:
movie_ids, distances = model.get_recommendations(movie_input, 5)
recommendations = movies[movies.movieId.isin(movie_ids)].reset_index()
recommendations['distances'] = distances
fig, ax = plt.subplots(1,1, figsize=(3,5))
sns.barplot(data=recommendations, y='title', x='distances', orient='h')
plt.show()