Singular Value Decomposition#
Singular Value Decomposition is explored on details here.
Machine Learning Exploration : Singular Value Decomposition
[1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
[2]:
ratings = pd.read_csv('/opt/datasetsRepo/RecommendationData/ratings.csv')
ratings.head()
[2]:
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 |
| 1 | 1 | 3 | 4.0 | 964981247 |
| 2 | 1 | 6 | 4.0 | 964982224 |
| 3 | 1 | 47 | 5.0 | 964983815 |
| 4 | 1 | 50 | 5.0 | 964982931 |
[243]:
movies = pd.read_csv('/opt/datasetsRepo/RecommendationData/movies.csv')
movies.head(5)
[243]:
| movieId | title | genres | |
|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 1 | 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
[3]:
idx_to_userid_mapper = dict(enumerate(ratings.userId.unique()))
userid_to_idx_mapper = dict(zip(idx_to_userid_mapper.values(), idx_to_userid_mapper.keys()))
idx_to_movieid_mapper = dict(enumerate(ratings.movieId.unique()))
movieid_to_idx_mapper = dict(zip(idx_to_movieid_mapper.values(), idx_to_movieid_mapper.keys()))
ratings['user_idx'] = ratings['userId'].map(userid_to_idx_mapper).apply(np.int32)
ratings['movie_idx'] = ratings['movieId'].map(movieid_to_idx_mapper).apply(np.int32)
ratings.head(5)
[3]:
| userId | movieId | rating | timestamp | user_idx | movie_idx | |
|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 | 0 | 0 |
| 1 | 1 | 3 | 4.0 | 964981247 | 0 | 1 |
| 2 | 1 | 6 | 4.0 | 964982224 | 0 | 2 |
| 3 | 1 | 47 | 5.0 | 964983815 | 0 | 3 |
| 4 | 1 | 50 | 5.0 | 964982931 | 0 | 4 |
[251]:
movies['movie_idx'] = movies['movieId'].map(movieid_to_idx_mapper).dropna()
movies.head(5)
[251]:
| movieId | title | genres | movie_idx | |
|---|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy | 0.0 |
| 1 | 2 | Jumanji (1995) | Adventure|Children|Fantasy | 481.0 |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance | 1.0 |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance | 482.0 |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy | 483.0 |
non mapped movies. i.e. non rated movie by any user.
[474]:
movies[movies.movie_idx.isna()].shape
[474]:
(18, 4)
User Movie Matrix#
[32]:
user_movie_matrix = ratings.pivot_table(values=['rating'] ,index=['user_idx'], columns=['movie_idx'])
user_movie_matrix.head(5)
[32]:
| rating | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| movie_idx | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 9714 | 9715 | 9716 | 9717 | 9718 | 9719 | 9720 | 9721 | 9722 | 9723 |
| user_idx | |||||||||||||||||||||
| 0 | 4.0 | 4.0 | 4.0 | 5.0 | 5.0 | 3.0 | 5.0 | 4.0 | 5.0 | 5.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | 2.0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 4.0 | NaN | NaN | NaN | 4.0 | NaN | NaN | 4.0 | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 9724 columns
[34]:
X = user_movie_matrix.fillna(0).values
Mask for NaN values#
[441]:
M = ~np.isnan(user_movie_matrix.values)
M
[441]:
array([[ True, True, True, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[ True, True, False, ..., False, False, False],
[ True, False, False, ..., False, False, False],
[ True, False, True, ..., True, True, True]])
[35]:
X.shape
[35]:
(610, 9724)
SVD Calculation#
[36]:
U, S, VT = np.linalg.svd(X, full_matrices=False)
U.shape, S.shape, VT.shape
[36]:
((610, 610), (610,), (610, 9724))
Eigen values plot#
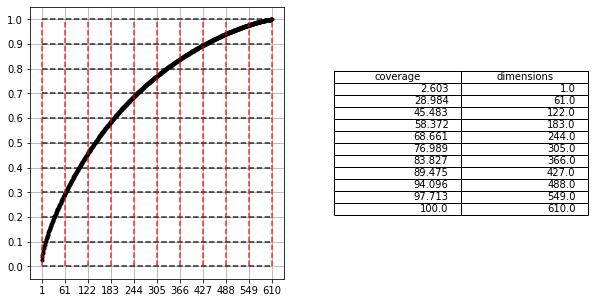
[435]:
deciles = (np.linspace(0,1,11)*100).astype('int')
deciles
[435]:
array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100])
[436]:
dims = np.linspace(1, len(S), 11).astype('int')
dims
[436]:
array([ 1, 61, 122, 183, 244, 305, 366, 427, 488, 549, 610])
[458]:
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
eig_value_coverage = S.cumsum()/S.sum()
coverage = np.round(eig_value_coverage[dims-1]*100, 3)
table = np.c_[coverage, dims]
ax[0].plot(eig_value_coverage, ".-", color='k')
ax[0].hlines(deciles/100, xmin=0, xmax=len(S), alpha=0.8, color='k', linestyle='--')
ax[0].vlines(dims, ymin=0, ymax=1, alpha=0.8, color='r', linestyle='--')
ax[0].set_xticks(dims)
ax[0].set_yticks(deciles/100)
ax[0].grid()
ax[1].table(cellText=table, colLabels=['coverage', 'dimensions'], loc='center')
ax[1].axis('off')
plt.show()
Low Rank Matrix#
[443]:
def low_rank_matrix(U, S, VT, rank):
X_tilde = U[:,:rank] @ np.diag(S[:rank]) @ VT[:rank, :]
return X_tilde
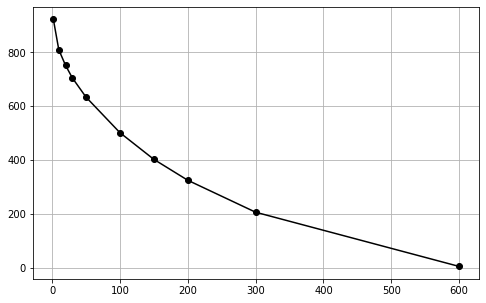
Loss : RMSE#
[452]:
def loss(X, U, S, VT, rank, M):
X_tilde = low_rank_matrix(U, S, VT, rank)
return np.sqrt(np.square(X - X_tilde, where=M).sum())
[459]:
l_losses = []
ranks = [2, 10, 20, 30, 50, 100, 150, 200, 300, 600]
for i in ranks:
l_losses.append(loss(X, U, S, VT, i, M))
fig, ax = plt.subplots(1, 1, figsize=(8,5))
ax.plot(ranks, l_losses, 'ko-')
ax.grid()
plt.show()
single prediction#
[460]:
def get_prediction(user_idx, movie_idx, U, S, VT, rank):
return U[user_idx,:rank] @ np.diag(S[:rank]) @ VT[: rank, movie_idx]
[461]:
get_prediction(0, 0, U, S, VT, 2)
[461]:
2.4850892043557016
user idx based top non watched/rated movie recommendations#
[462]:
user_movie_matrix.index
[462]:
Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
...
600, 601, 602, 603, 604, 605, 606, 607, 608, 609],
dtype='int64', name='user_idx', length=610)
[469]:
user_idx = 10
rank = 100
[476]:
user_vector = user_movie_matrix.iloc[user_idx].values
user_vector
[476]:
array([nan, nan, 5., ..., nan, nan, nan])
[478]:
non_rated_movies_idx = np.isnan(user_vector)
non_rated_movies_idx
[478]:
array([ True, True, False, ..., True, True, True])
[479]:
all_movies_ratings = get_prediction(user_idx, ..., U, S, VT, rank)
all_movies_ratings
[479]:
array([ 1.17833575, -0.08102169, 1.9669552 , ..., 0.01067371,
0.01245267, 0.01245267])
[480]:
top_n_movies = 5
[481]:
top_n_idxs = np.c_[np.argsort(all_movies_ratings)][non_rated_movies_idx][::-1][:top_n_movies, 0]
top_n_idxs
[481]:
array([ 7, 20, 25, 463, 34])
[482]:
movies[movies['movie_idx'].isin(top_n_idxs)]
[482]:
| movieId | title | genres | movie_idx | |
|---|---|---|---|---|
| 97 | 110 | Braveheart (1995) | Action|Drama|War | 7.0 |
| 123 | 150 | Apollo 13 (1995) | Adventure|Drama|IMAX | 463.0 |
| 314 | 356 | Forrest Gump (1994) | Comedy|Drama|Romance|War | 20.0 |
| 398 | 457 | Fugitive, The (1993) | Thriller | 25.0 |
| 510 | 593 | Silence of the Lambs, The (1991) | Crime|Horror|Thriller | 34.0 |